|
TelcoMgr File Structures |

|

|

|
|
TelcoMgr File Structures |
|
|
|
Anatomy of a Database
This section briefly describes the fundamentals of database design. It is meant only to provide an overview of the subject for those who are not already thoroughly familiar with standard database design concepts and issues. Experienced users may want to move right on to the next chapter and skip this section.
Definitions
A database is a collection of information (data) in a system of tables, rows, and columns. The database is maintained by one or more computer programs or applications.
The basic unit of data storage is a column. A column is a storage place for information of a similar type. For example, one column might store a name and another column might hold a telephone number. A group of different columns that are logically related make up a row. A row contains all the information related to one subject. For example, all the columns containing information concerning one student (name, address, telephone number, student number, etc.) makes up one student’s row. This would be similar to a file folder a school might keep for each student.
Collections of logically related rows make up a table. Using the same example, a collection of all students’ rows makes up the student body table. This would be similar to the file cabinets where students’ folders are kept.
Another way of looking at this is as a table or spreadsheet:
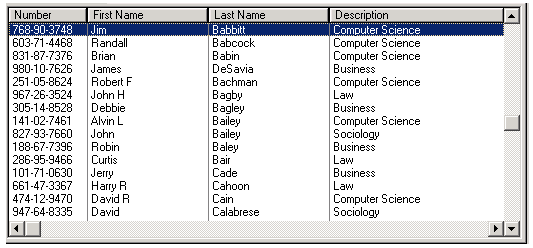
In this format, the entire table is a file cabinet, with rows (folders) and columns (data about one row).
A database is a collection of related tables. This is similar to a bank of file cabinets where the entire school records are kept. One file cabinet might hold the files with students’ personal data, another with class enrollment information, and another with faculty information.
A relational database is a collection of tables with defined relationships between them. Effective database design breaks the data into related tables that are joined together through linking columns. This will be covered in detail later in this section.
Summary
| • | One or more columns combine to form a row. |
| • | One or more rows combine to form a table. |
| • | A collection of related tables is a database.*This documentation reflects the files structures for TelcoMgr version 5 and subject to change without notice. |
User Tip: Export a TelcoMgr Locaton, Circuits and/or Directory file as a Comma Separated Value (CSV) file to create a file template for importing data.
User Tip: IMPORT THE LOCATION FILE FIRST SO TELCOMGR CAN CREATE THE CUSTOMER SYSTEM ID (CusSysID) number automatically. The appropriate CusSysID must appear in each record that is imported into the CIRCUITS and DIRECTORY files.
CSV or EXCEL data may be imported into the following TelcoMgr files.
| 1) | telco.tps - The Customer/Location file is classified as the PARENT file and the master relationship is set by the CusSysID field, which is common to the CHILD files below: |
| a) | circuits.tps - The CIRCUITS file contains the physical and logical data descriptions of each circuit, including lines, features, services, charges and taxes. The CusSysID field is related to the telco.tps CusSysID field. |
| b) | directry.tps - The DIRECTORY file contains users names, extension numbers and DID numbers and is related to the telco.tps file. |
| c) | cpe.tps - The CPE file may be used for variety of purposes, which includes components, systems, individual equipment, etc. and the PARENT to the COMPONENTS file. |
| i) | componts.tps - The COMPONENTS file is a CHILD of the CPE file and includes detailed information about equipment/system components. |
Reserved Fields
The TelcoMgr [Reserved] fields are numeric auto-increment fields which are automatically generated by TelcoMgr, therefore data should not be imported into a [Reserved] fields.
Review the field layout for each file to learn which fields are [Reserved] fields.
Page url: http://impex.sword-field-service-software.com?file_structures.htm

